数组
概念
Go 语言中的数组是一种 值类型(不像 C/C++ 中是指向首元素的指针)
1 | |
当把arr1一个数组赋值给另一个时,需要在做一次数组内存的拷贝操作。如果你想修改原数组,那么 arr1 必须通过&操作符以地址方式来传递。
把一个大数组传递给函数会消耗很多内存。有两种方法可以避免这种现象:
- 传递数组的指针
- 使用数组的切片
编译时需要知道数组长度以便分配内存,所以数组长度必须是一个常量表达式,并且必须是一个非负整数,数组长度最大为 2Gb。数组长度也是数组类型的一部分,所以[5]int和[10]int是属于不同类型的。
声明数组时所有的元素都会被自动初始化为默认值。
数组常量
如果数组值已经提前知道了,那么可以通过 数组常量 的方法来初始化数组,而不用依次使用 []= 方法
1 | |
可以取任意数组常量的地址来作为指向新实例的指针。
1 | |
多维数组
数组通常是一维的,但是可以用来组装成多维数组,例如:[3][5]int,[2][2][2]float64。
切片
概念
切片(slice)类型。这是一种建立在 Go 语言数组类型之上的抽象,是对数组一个连续片段的引用(该数组我们称之为相关数组,通常是匿名的),所以切片是一个引用类型(因此更类似于 C/C++ 中的数组类型,或者 Python 中的 list 类型)。这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。需要注意的是,终止索引标识的项不包括在切片内。
切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量。
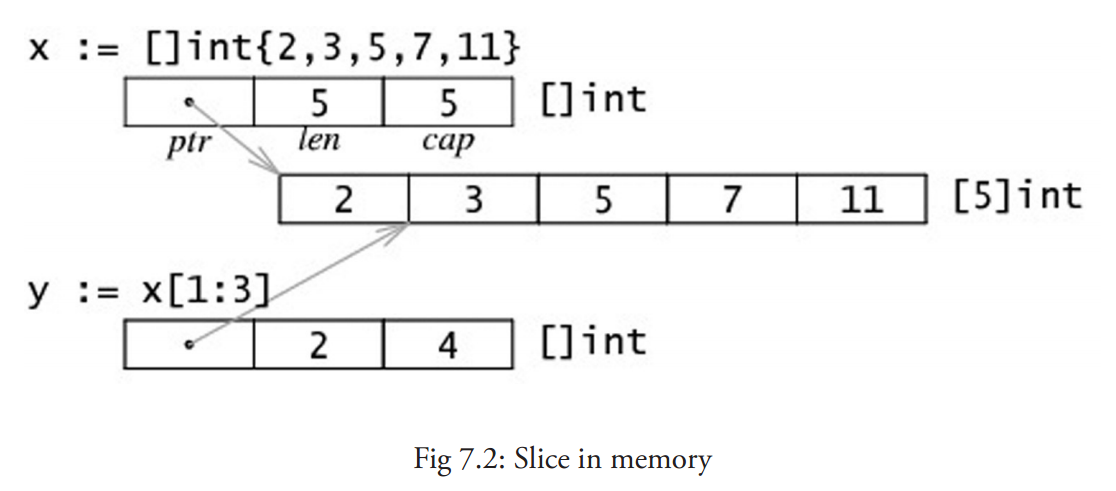
声明切片的格式是: var identifier []type(不需要说明长度)。
一个切片在未初始化之前默认为 nil,长度为 0。
切片的初始化格式是:var slice1 []type = arr1[start:end]。
切片也可以用类似数组的方式初始化:
1 | |
new() 和 make() 的区别
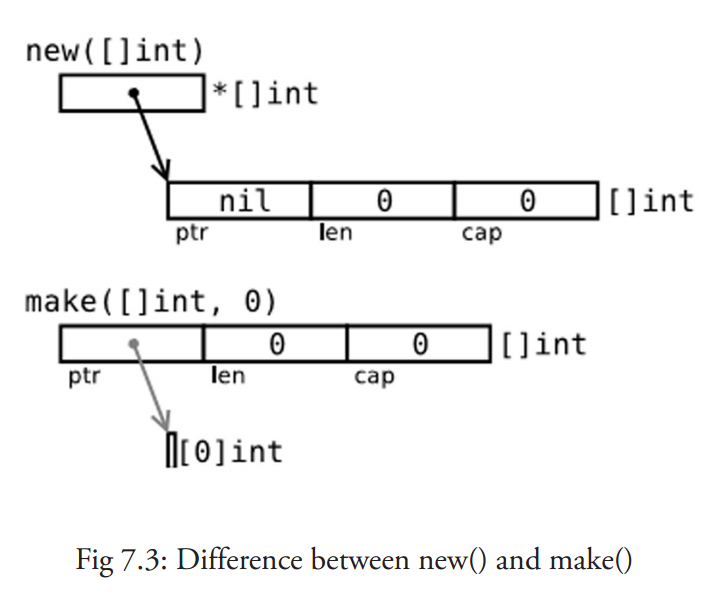
new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为*T的内存地址:这种方法 返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体,它相当于 &T{}。
make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel。
原理
1 | |
切片提供了一个与指向数组的动态窗口。
1 | |
切片作为参数传递时,函数接收到的参数是数组切片的一个复制,虽然两个是不同的变量,但是它们都有一个指向同一个地址空间的array指针,当修改一个数组切片时,另外一个也会改变,所以数组切片看起来是引用传递,其实是值传递。
对切片进行append操作是,如果导致了扩容的情况,那么新的切片中array不再指向原来的数组的首元素的地址,所以对这个切片的元素进行修改,无法影响到原有的数组或使用这个数组的其它切片。
可以用传递切片地址的方式来保证对切片的修改一定会在原有切片上生效。
1 | |
nil和空切片
nil 切片被用在很多标准库和内置函数中,描述一个不存在的切片的时候,就需要用到 nil 切片。比如函数在发生异常的时候,返回的切片就是 nil 切片。nil 切片的指针指向 nil。
空切片一般会用来表示一个空的集合。比如数据库查询,一条结果也没有查到,那么就可以返回一个空切片。
1 | |
空切片和 nil 切片的区别在于,空切片指向的地址不是nil,指向的是一个内存地址,但是它没有分配任何内存空间,即底层元素包含0个元素。
最后需要说明的一点是。不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。